
In the previous two posts in this series, we saw that created a connected product, is of itself no guarantee of creating a successful business stream. While connectivity can provide great customer experiences, this only leads to a sustainable product strategy if there is a continuous revenue stream behind the proposition, either directly from the customer, or indirectly through other parties.
The key to generating this on-going revenue, and with it, long-term sustainability, is using the data collated by connected products to create Smart Features. We have already seen here as to how the machine learning, analytics and AI can transform a merely ‘connected’ product into a truly smart one. But what are the pitfalls? Why isn’t everyone doing it? This blog post examines some of the challenges and proposes a set of principles to help guide navigating the murky waters of using Smart Algorithms (which from this point onwards I will use as lazy shorthand for the vast spectrum of machine learning and artificial intelligence algorithms).
First of all, it’s difficult!
In many ways, we are living in an AI golden age. Artificial Intelligence and Machine Learning have never been so accessible to those without the PhDs and mathematical nous to create the algorithms behind most smart features. The giants of the cloud computing space, Microsoft, Amazon and Google offer a vast array of capabilities and services that make the creation of smart services available to all. Cheap, ‘pay-as-you-go’ compute and storage means that large up-front investment in hardware is no longer necessary. Open-source machine learning toolkits mean that anyone can make use of cutting-edge algorithms in creating a smart product. Rapidly cloud scalable computing platforms, making use of technologies such as containers and serverless functions means that once created, these services can be deployed at scale and ramped up rapidly. None of this would have been possible just over five years ago.
So what’s the problem? In a nutshell, having all this tech at your disposal makes creating Smart Features possible, but not easy. It is just as the widespread availability of fighter jets would not automatically create a nation of fighter aces. 
It is fairly widely reported (see below) that despite all the hype about AI, most AI and big data projects fail, with figures up to 80-90% quoted, with problems quoted including lack of skilled AI engineers, fragmented and inconsistent data, and a lack of proper return-on-investment analysis. So how do you avoid all these pitfalls?
1. Start small and focus on a clear problem
One of the challenges when faced with a big data opportunity is that of identifying where to start. Your connected devices and business systems may be generating tonnes of data – telemetry, customer behaviour, transactions, interaction data. This may well feel overwhelming, while at the same time be fragmented, owned by different parts of the business, and appear to be more of a data swamp than a data lake. All successful Smart Products start with a clear problem and an associated benefit hypothesis. At its most basic, it is about identifying the question that needs to be answered, and as being as specific as possible in doing so.
Take Spotify, who set out to convert the world’s largest collection of music into something that is seamlessly accessible by its users. In the parlance, how do you make music ‘discoverable’ by users who may not know the names of the artists they listen to. The benefit hypothesis was that they could create a recommendation engine that would use the listening history of both individual users and the overall user base to propose music that its users would enjoy. This was a clear problem statement, which resulted in Spotify’s Discover Weekly playlist, which is playing in the background as I write this blog.

2. Set clear product success metrics and measure yourself against them
No matter how smart an algorithm is, unless it provides a clear user benefit it is unlikely to be monetisable. It is therefore critical to be able to measure the success of the product, either directly or indirectly. What is not measurable or testable is not improvable, and there is no way of telling whether the smart algorithm is adding value. Crucially, these metrics should be in terms of what drives the product or business success, and not focused on the technical merits of the underlying algorithms.
For example, consider Gmail‘s, at times rather spooky, “Smart Compose” feature which provides suggestions for how to complete or continue a sentence. A valid metric would be the percentage of times users select the automatically generated text, rather than ignoring the proposal. Similarly, consider LinkedIn’s automated Recommended Jobs. Three parties have a vested interest in its success. Candidates want to be presented with relevant jobs (measured by the number of jobs applied for), recruiters with relevant candidates (measured by the number of considered applications) and LinkedIn itself wants to increase the number of users subscribing for its paid-for service. To succeed, all three business metrics need to be met.
3. Can this be solved by ML? If so, identify the type of problem
Remember, most AI projects fail, so now’s the time to start asking whether Smart Algorithms are the solution to your problem. This is something that needs to be kept in mind throughout the process. The first step to answering the question is to determine whether the customer or business problem to be solved can be decomposed into one or many known machine problems. This is where the computer science begins. As hinted previously, there is a large toolkit of AI algorithms readily available. Typical problems include making predicting a future value of an item (e.g. stock price predictions), recommending an outcome (e.g. Search engine results), classification (e.g. email spam filtering, facial recognition), pattern recognition (e.g. also price predictions). Additionally, there is a class of machine learning algorithms, called Deep Learning which makes use of programmable neural networks to make decisions. The latter class of algorithms are what is closely referred to as AI and are used typically for applications such as Google’s translate service and Facebook’s image annotation and tagging features. In reality, most sophisticated products will use a combination of algorithms to produce the desired outcomes. For example, Spotify’s Discover Weekly combines natural language processing, audio characterisation and analysis and collaborative filtering. (For more details, see here)
For example, Google’s online Machine Learning course suggests the following examples of supervised and unsupervised machine learning prediction tasks.

4. Create the right tech capability
Smart algorithms are defined by some very challenging characteristics. First, they need large amounts of good quality, clean, data to work. Never has the old adage of garbage-in, garbage-out been so true. Secondly, you are now interacting with your users on a non-trivial level, no longer just switching things on or off or automating an action. Instead, you are engaging at a more emotional level, assisting them, replacing what would otherwise be a thought-out human decision process. Your algorithms are now suggesting answers to questions such as “what does this mean?”, “Is this a safe place?”, “What shall I watch?”, “What sort of exercise should I do?” The user experience and user interaction implications are now significant. For example, it is not trivial to discern the distinction between what is helpful and what is intrusive or indeed downright creepy.
Finally, Smart Algorithms are no longer characterised solely by software that can be easily tested in isolation. An algorithm is the product of input data that is used to train the algorithms (more on that later), the combination of algorithms used and associated parameters, the code itself, and any feedback or learning loops involved. The performance of Smart Algorithms can, therefore, be unpredictable and vary according to changes in circumstances. For example, an Amazon internal AI-based recruitment tool was found to have an anti-female bias, presumably because it was trained on datasets of male candidates. Famously, a Microsoft chatbot ‘learnt’ to spout misogynist and Nazi opinions through its interactions with users, not quite what its creators intended.
So how do we avoid all these pitfalls?
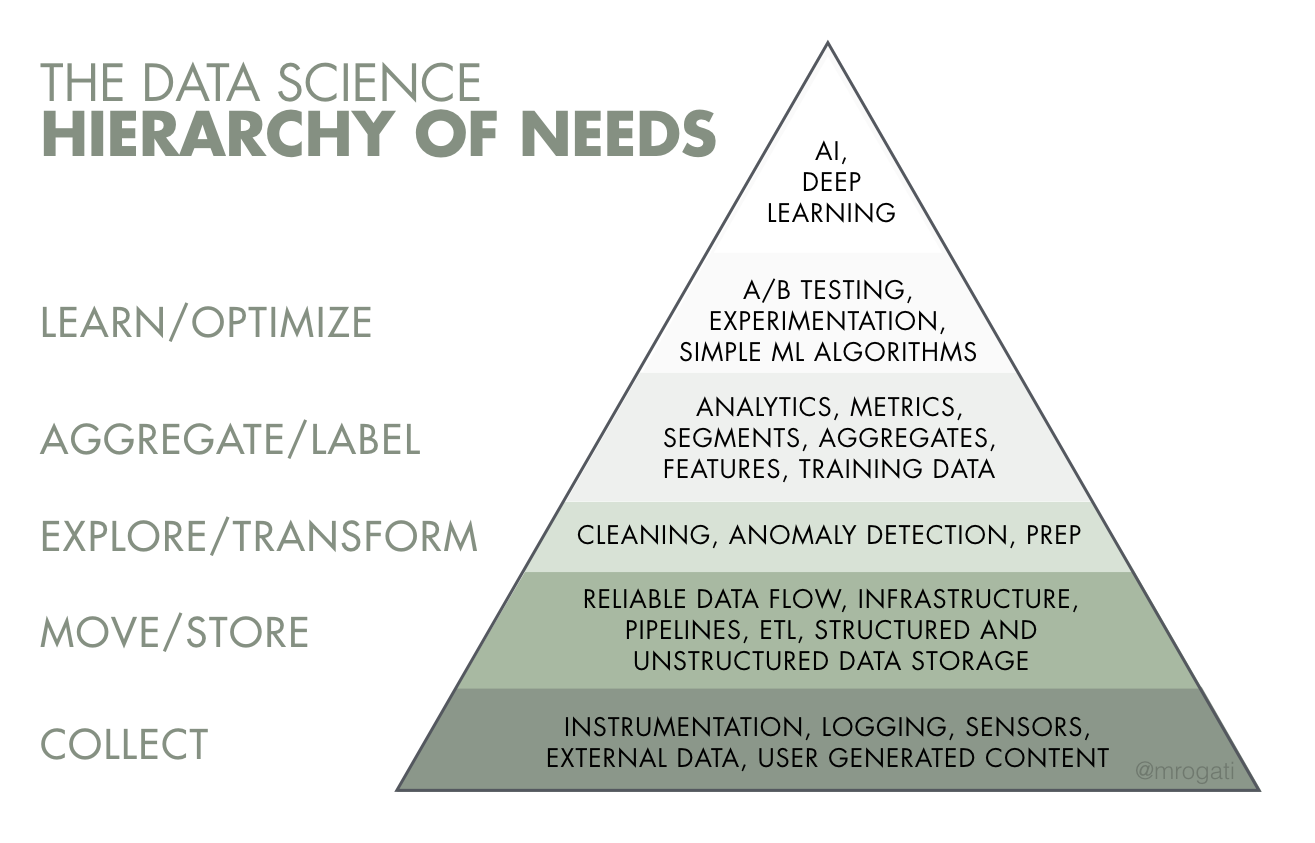
The answer is to create the right tech capability to deal with the entire machine learning pipeline on an end-to-end basis robustly and iteratively. This is described very effectively as a Maslow-like hierarchy by Monica Rogati as shown below. The message here is clear. Before you can aspire to create products using Smart Algorithms, you need to master the entire data manipulation workflow and be capable of running robust and verifiable experiments.
The process of creating a developing a Smart Algorithm can be also be described as a linear process divided into two principal phases. The first involves creating the algorithm itself, preparing and cleaning the data and selecting which type of machine learning solution is best suited. The model will need to be ‘trained’ and tuned using a representative set of real-world data, and once this is tested, it can be deployed as part of a product. Typically the model is then used to make predictions or decisions based on the data it encounters in the real world.

5. Assume you will get it wrong. Iterate, iterate, iterate!
It would be wrong however to give the impression that a linear approach to creating a Smart Product will lead to success.
We have already considered the specific challenges in dealing with Smart Algorithms. Consider for example the granddaddy of smart products, the Nest Learning thermostat. The product premise was very simple. The thermostat will automatically create a schedule based on the interactions with its users. However, the early examples were beset with problems. An excellent paper from 2013 describes how one user felt that “it is too controlling and not enough adaptive to our immediate needs.” Someone else said, “everything was straightforward but learning.” Another entry stated, “it’s unclear to me whether the learning is done, or if it is continuing to learn patterns.” As a result of this early feedback, the Nest engineering team set about creating new mathematical models and control algorithms to improve the product.
This highlights a key point, namely the need to deploy the product in a controlled environment and assess the technical and user dimensions of the product. At each stage of the development and operations (DevOps, anyone?) of the product, it is important to build feedback loops to correct, fine-tune and improve the product. The product development workflow will therefore have to include iterative or feedback loops. These fall into three main categories:
- Iterate model development – This initially takes place before product launch and involves decomposing the user problem into machine problems, iteratively cleaning and transforming the data and selecting and fine-tuning the chosen algorithms.
- Iterate the product. Once launched, it is critical to measure the product’s performance, both in terms of its technical characteristics (e.g. how accurately a thermostat tracks desired temperatures) as well as in terms of user behaviours (are users choosing to use the product in ‘learning mode’?). These learnings are then used to improve the model
- Dynamic training In the two examples above, the model is improved offline (i.e. in a development environment) and then the product is improved as part of a software update. Self-learning models make use of dynamic training and can refine their model while in operation as new data is made available. The risk here is that as in the case of the ‘Nazi chatbot’, the model can evolve towards something that is not well understood by its own creators.

6. Apply Continuous Delivery Principles – MLOps
The relentlessly iterative approach to updating and tuning smart algorithms requires that all stages in the process are treated with the rigour of a scientific experiment, empirically proving or disproving hypotheses. In doing so, there are three facets of the problem that need to be managed: The code itself, the model and associated experiments, and the data used to train the models.

Just as Continuous Delivery introduced DevOps to the world, encouraging us all to manage all changes in the software production process and automate all testing associated with its creation, the same approach can be applied to Machine Learning. Variously known as Continous Delivery for Machine Learning (CD4ML) or Machine Learning DevOps (MLOps), this is described brilliantly in an article by Danilo Sato et al, and I will pick up some of the main themes.
This approach maintains all the organisational principles associated with DevOps, including the use of cross-functional teams, issuing updates in small increments, releasing software at will and use of short development cycles. The latter is critical for implementing the feedback loops described above. Additionally, MLOps (I find this term snappier than CD4ML) ensures that the data-specialists involved in creating Smart Products (data engineers, data scientists, machine learning engineering, development, operations, product owners) are brought together in collaborative teams. Moreover, the same disciplines that DevOps teams have been using for a while are extended to all aspects of Smart Algorithms.
The authors emphasise the following principles:
- True end-to-end team ownership – If the people responsible for the creation of ML models are not also accountable for implementing the models and supporting them, then it will be difficult to create products that successfully leave the Proof-of-Concept phase and scale to production.
- Manage and track all artefacts – Given that the training data, and indeed sometimes the production data is a function of how a smart product has come into being, it is only possible to reproduce the development steps if configuration management is applied to all stages of model development.
- Model Deployment and Monitoring– Iterative improvement of the smart algorithms requires a deployment strategy that facilities monitoring of performance and rapidly deploying new models.
- Model Testing – The test strategy needs to accommodate the specific needs of smart algorithms. Typical issues that arise include ensuring that the models are not over-fitted to the specific data used for training, making sure that the models can deal with unexpected inputs and ensure that they are validated against bias.
Conclusion
Although products that use Machine Learning hold great promise, there is a reason why they are not more widespread, and why the Googles and Facebooks of this world currently dominate this space. To those companies that get it right – see Spotify, the rewards are substantial.
Sustainably creating a successful and profitable pipeline of smart products, rather than simply being a one-hit-wonder, requires a high degree of organisational sophistication and finely-tuned technological orchestration. This is not an area where a product manager can create some user stories and throw over a wall to a development team. It requires strong customer focus across the team as well as truly cross-functional working including product managers, UX experts, data scientists, data architects and DevOps practitioners working to clear metrics. The software development pipeline must be robust and be capable of managing datasets, models and code iteratively and in a repeatable fashion through development and production environments, taking smart products through the product creation loop time and time again. Fail in any one of these, and you are unlikely to repeatedly create Smart Products.
Further Reading
- Why Spotify’s Discover Weekly Playlists Are Such A Hit
- Smart Compose: Using Neural Networks to Help Write Emails
- Introduction to Machine Learning Problem Framing – Google
- The Hierarchy of AI Needs
- Yang, Newman, Learning from a Learning Thermostat: Lessons for Intelligent Systems for the Home
- Continuous Delivery for Machine Learning
- What would machine learning look like if you mixed in DevOps? Wonder no more, we lift the lid on MLOps
- ML Models – Prototype to Production