
A list of Artificial Intelligence Good Reads, trying to make sense of the fastest moving space in tech since the advent of the Internet. This is the smallest tip possible of an unmanageable iceberg. Here are a handful of initial articles. I will update this over the next few days. Enjoy! (Image courtesy of DALL-E-2)
December ’23
EU agrees new AI legislation
The EU Commission and European Parliament this week agreed the outline of an EU-wide AI Act that aims to provide safeguards on the use of advanced AI models. The proposed legislation forbids the use of AI algorithms in a number of application, including the use of tracking people through facial recognition (except for law enforcement) or for the purposes of ‘social scoring’. Companies will also have transparency obligations on the inner-workings of advanced models and the data that was used for training, and will be required to comply with a number of safety mechanisms including risk assessments, benchmarking and adversarial testing. It is notable that companies such as OpenAI and Google’s DeepMind have so far resisted calls for this sort of disclosure.
Google announces its Gemini family of multimodal AI models
Just last week, I wrote about Mirasol3B, a multimodal AI model, and this week that news is already old hat, as Google announced their flagship generative AI model, Gemini. This will be available in three flavours. The most performant of the three, known as Ultra, is said to outperform GPT-4 on most benchmarks. It is however not available for public use, and the version that is currently integrated into Bard is based on a less performant Pro version. (See here for the full technical report, and a critique here). Having played around with Gemini Pro on Bard, the experience is fairly similar to ChatGPT (based on GPT-4), but it clearly has a more up-to-date feature set. Looking forward to the general availability og Gemini Ultra.
MLOps – A primer
Whilst everyone involved in tech will be familiar with DevOps, the set of software engineering practices that span coding through to operation, its equivalent in the AI space, MLOps (Machine Learning Ops) is not as well known. The behaviour of machine learning and AI models is less predictable than traditional software, as it depends on the data used for training, the model structure and its parameters, the inputs used in production, as well as the software that hosts and interacts with the model. As such productising machine learning in a way that is safe, reliable and repeatable requires a structured approach to how data, models and software are managed, based very much on DevOps principles. Databricks provides a nice summary of the key elements.
Older posts…
Google’s new multimodal AI model
As AI models become ever more sophisticated, one of most challenging problems is how to combine different media types together. Video, audio and text data all have very different characteristics in terms of how they are represented in data as well as the AI models used to process them. This means that creating an AI model that can manipulate all forms of media is proving to be a big challenge. A couple of weeks ago, Google DeepMind announced a new model, called Mirasol3B that implements multimodal learning across audio, video and text in an efficient way. The draw for Google is obvious – how can it combine its vast YouTube catalogue in a meaningful way with its enormous largely text-based search engine. Although benchmarking indicates that this model may have broken new ground, researchers have criticised it for the opaqueness on how it works.
Using the Human Brain as a template for more efficient AI models
Although it is often claimed that neural netwrorks are modelled on human brains, the vast amounts of material that generative language or image models consume during their training bears little resemblance to how humans learn. Humans are clearly much more constrained in terms of the energy they consume when learning or problem solving. In a recent paper in Nature Machine Intelligence magazine, scientists from the University of Cambridge have sought to model an artificial neural network that contained constraints similar to those found in a human brain. The research showed that these constraints influenced the model to seek more efficient ways of solving problems. This obviously has very interesting implications for the development of AI models, particularly in designing systems that are both adaptable as well as efficient.
Anthropic’s ChatGPT rival sets an important benchmark
Anthropic, the startup backed by Amazon and Google, announced that Claud 2.1, its Large Language Model can process inputs with up to 200,000 tokens at once, equivalent to 500 pages of text. For comparison GPT-4 supports a token length of 8,000 or 32,000, depending on the model used. Token length, also known as the context window, is important as it represents the quantitiy of input information that it can consider when generating text. For example, this sets the upper limit on text it can summarise, or sets a limit before it can no longer ‘remember’ the previous context.
The hidden manual effort in creating AI models
Many generative AI systems, such as OpenAI’s GPT family of Large Language Models make use of human labelling to fine-tune and improve the prediction models, in a technique called “Reinforcement Learning from Human Feedback” (RLHF). A Wired article last month explored who carries out this data labelling. The article described how workers in places such as Venezuela, Colombia, east Africa, the Philippines and Kenya manually label images, outputs from large language models as part of their training process.
The Open Source vs Proprietary AI Models Faultlines
A row has escalated in the past few weeks over the relative threats to public safety of open-source and proprietary AI models. Meta, who famously released the inner workings of its Llama 2 models has come under criticism by some safety advocates who claim this lowers the bar for malicious third parties to use LLMs for nefarious purposes such as cybercrime or developing harmful biological or chemical agents. Unsuprisingly, OpenAI and Meta are on opposite sides of these faultlines, with Sam Altman, OpenAI’s CEO claiming that its closed proprietary model provides the best safeguards against exploitation. Yann LeCun, Meta’s head of AI and one of the godfathers of AI development, strongly makes counter-arguments that the very nature of closed AI systems makes their risks unknowable and can create a monopoly that concentrates humanity’s knowledge into black boxes is a threat to democracy and diversity of opinion.
AI’s Regulatory Outlook
As big tech argues about the merits of open-sourced vs proprietary models, governments around the world are trying to figure out the best way to keep their citizens safe. Some AI luminaries such as Geoff Hinton, Elon Musk and Sam Altman are warning against the existential risks of artificial general intelligence (AGI), while others, including Meta, are more concerned about the more prosaic risk to competition of ‘winner takes all’ economics and the cost of regulatory compliance on open source models. Last week, the US Government issued an Executive Order which places requirements on the establishment of guidelines and best practices, carrying red teaming exercises on large models and requiring disclosure on how large-scale computing clusters are used. This was folllowed by the ‘Bletchley Declaration’ at the AI Safety Summit hosted in the UK that outlines an international consensus on the need for scientific and policy collaboration in the face of AI risk, but was somewhat short on practical measures.
Dealing with Prompt Hacking
Despite their size and sophistication, large language models (LLMs) are particularly sensitive to the instructions, or ‘prompt’ used to generate an outcome. In its benign form, this is sometimes called ‘prompt engineering’ and a quick scour of the web throws up prompt templates for anything from creating a CV to answering a high school essay question. The darker side of prompt engineering is ‘prompt hackingexploits’ which uses carefully constructed prompts to work around safeguards and bypass protections in the model. This includes ‘indirect prompt injection’ which exploit the ability of many LLMs’ to ingest data as part of the query. The combination of LLMs’ inherent opaqueness of their inner workings, plus their ability to make use of data of potentially concerning origins, means that they should always be treated with caution, following the cybersec principle of least privileges.
State of AI 2023
Nathan Benaich, of Air Street Capital, a VC focused on AI ventures, issues an annual “State of AI report”. The 2023 issue was published a couple of weeks ago and highlights that although GPT-4 currently sets the benchmark in terms of large language performance (it is actually a multi-model model, as it was trained on text and images), efforts are growing to develop open source models that match the performance of proprietary models. Interestingly, the largest models are running out of open human-generated data that can be used to train them. The report provides a nice summary of the key research highlights of the year, where industry is investing, the political and safety implications and predictions for 2024. At 163 slides, it is a fairly hefty read.
October ’23
Towards AI Safety (1) – On Mechastic Interpretability
One of the (many) challenges in understanding how neural networks really work is that there is no easily-observable logic to how they actually work. They are not governed by simple mathematical relationships, making them very difficult to diagnose problems, or explain why they predict certain outcomes. The same is true for neuroscientists, who struggle to understand the function of individual neurons in the brain. Anthropic recently published a paper that describes how a large language model can be decomposed into more coherent features, e.g. describing themes such as legal language or DNA sequences, and then use another LLM to generate short descriptions of the features, through a process called “autointerpretability”. This work is aimed to provide a mechanistic model of how neural networks work in order to overcome concerns about their use in safety or ethically-sensitive applications.

Decomposing Language Models Into Understandable Components
Towards AI Safety (2) – Watermarking AI Images
In July, the White House announced that the main large tech companies had agreed to deploy watermarks to determine in a robust way whether they have been generated by their generative AI models. Watermarking involves adding patterns that are difficult to remove from the image that attest to their origin. The Register however reports that a team at the University of Maryland demonstrated that they were able to attack such schemes, both degrading the watermark (i.e. allowing an AI-generated image to skip detection) as well as making non-watermarked images appear as though they are AI-generated. It seems that there is way to go until we have robust systems to identify deepfakes.
Towards AI Safety (3) – Tackling Algorithmic Bias
As AI models, including generative AI models such as ChatGPT, Stable Diffusion, as well as other tools such as classifiers, fraud detectors, credit scoring algorithms and so on are trained on large sets of data, often from the Internet and other public datasets, they contain and reflect the biases contained within them. So, we have seen how a recruitment tool used by Amazon a few years ago showed bias against women as it was trained on the male-dominated applicant pool, while more recently AI-generated barbies displayed all the national stereotypes you might fear (including a German SS officer Barbie!) . An Article in Vox recently provided an overview on why fixing AI bias is so difficult, why it is everywhere, who is most negatively impacted (no prizes for guessing!) and some of the initiatives underway to tackle the problem.
AI’s Environmental Impact
A recent article in the NY Times quoted an analysis that predicted that by 2027 AI servers would use between 85 to 135 TWh annually, equal to the entire electricity consumption of Sweden, and 0.5% of the world’s electricity. For context, all data centres in 2022 consumed between 1 and 1.3% of the world’s electricity (excluding crypto-mining), and in 2021 was already responsible for 10-15% of Google’s electricity consumption. As many AI training techniques are at their infancy, as AI scales further, a paper by MIT predicts that the algorithms will be optimsed for efficiency and not only for accuracy, for example by stopping underperforming models or tracks early. There is definitely a sense that so far, in the race for AI headlines, all secondary considerations have been put aside. Even if companies and cloud providers are not driven by environmental concerns, the likely constraints on GPU supply will be sufficient motivation to push for algorithmic efficiency.
Previous articles
Generative AI copyright gets thorny
While Hollywood actors and writers are on strike, partly trying to protect themselves against AI-created derivatives of them and their work, a US federal court has rules that generative AI work will not be protected under US copyright law. In the ruling, the judge stated that although “copyright is designed to adapt with the times… (it) has never stretched so far, however, as to protect works generated by new forms of technology operating absent any guiding human hand.” In a related development, Microsoft have decided that they will underwrite and defend any customer of its Copilot AI services (which includes its generative coding tools) from any copyright infringement suits.
A closer look at Meta’s Open-Source alternative to Chat GPT
We have already looked at the impact of open-source large language models as an alternative to ChatGPT. These have the clear advantage that they can be used and trained on domain-specific data and thus be optimised to solve specific tasks, as exemplified by Bloomberg’s financial analysis model. Moreover, as the underlying model and training approaches are public, their strengths, limitations, biases and vulnerabilities are open to inspection. This article provides an overview of Lllama 2 as well explaining how to get your hands on the model and have a play with it yourself. The open source nature of LlaMa2 has stimulated an industry’s worth of activity tailoring it for specific applications, such as Colossal-AI’s large-scale training solution.
Exploring an LLM software stack
An article describing Colossal AI’s large-scale LlaMa 2 model training solution also provides a pretty clear outline of a typical software stack for training and operating large language models. Worth reading just for this.

Artificial Intelligence at the Edge – Looking at TinyML
Much of the discussion relating to the future of machine learning and generative AI models focuses on how future applications will require larger, more computationally-expensive models, with more parameters and much larger training sets. There is however an alternative approach, which instead considers how best to distribute algorithms on cheap low-power edge devices. The advantages are obvious. If AI algorithms can be run on end devices, be they cars, home sensors, health monitors, agricultural sensors and so on, they do not need to be hosted and processed on a server somewhere. For large systems, this has a significant impact on system resilience, responsiveness and privacy, as devices can be intelligent themselves, rather than sending all data for processing elsewhere. Light-weight models such as TensorFlow lite are designed to operate on the smallest, most power-efficient chipsets to bring AI processing out of the data centre to the real world.
Updated 2 July
A dissenting view. Why AI may not be as revolutionary to the world economy as we are assuming.
This essay takes a number of steps back and frames AI in the context of its likely long-term societal impact. In other words, where will it sit compared to the inventions, say, of agriculture or the steam engine? The authors, including The Economist‘s economics correspondent, take a refreshingly dissenting view. Challenges that will limit its impact include: drowning in information and content generated by AI, legal constraints of getting computers to make decisions impacting humans, the not insignificant issue of physical world interactions, and the challenge of mimicking human expertise. I don’t agree with everything that is said here, but as a counterpoint to AI hype, this is a fantastic read.
Will we survive the flood of AI content?
In a previous release of this list, we referenced a paper that touched on the value of human work where AI-generated content is assessed by other AI models. An essay this week by Alberto Romano asks what happens when AI-generated content increases to the point where most content is created by statistical models designed to mimic human coherence. Only this week an author of fiction observed that 81 out in a top 100 chart of self-published Kindle content were AI-generated. Search engines and social media algorithms were tuned to identify an promote content people will find more useful. How will this work when most content is computer generated?
Meta’s Transparency Quest
Meta, is in many ways a surprising AI pioneer. No only is it making some of the more interesting forays into open-source models, (see links below), but it is also in explaining how all the relevant recommender and ranking mechanisms work across Facebook and Instagram. While the algorithms themselves are not described in any detail (assume Meta consider these to be their ‘secret sauce’), you can find all the input signals that are used to rank content. This is a lot more than we have learnt from the likes of OpenAI. See here for an interview on Nick Clegg, Meta’s VP of global affairs (and former UK deputy PM).
Not so Massive. Device-optimised generative AI
Large language models and large diffusion models for image generation, are, well, large, and are typically limited to server-based deployments. This week Google published a paper that describes how they have optimised the memory needs for large diffusion models, such that they can support image creation from text input in under 12 seconds on a high-end smartphone GPU. While it still requires 2GB of RAM to hold the model parameters. Whilst this paper speaks to the optimisations required for generative adversarial networks, I suspect, we will see a greater focus in reducing the size of inference models to allow for deployment on devices.
Operationalising Machine Learning
With most of the discussions online focusing on AI models, their applications and real-world impact, it is easy to ignore the engineering discipline required to keep an AI product maintainable, reliable and secure. Just as DevOps principles allow software engineers to reliably and frequently release code that works, MLOps (Machine Learning Operations) are essential for creating an auditable, testable, end-to-end ML/AI pipeline from data ingestion, through to model training and tuning, and deployment and management. The AWS blog site provides an overview of how AWS supports MLOps, while Google describes how to implement an automated AI pipeline on their Google Cloud platform.
AI Security Models
The OWASP (Open Worldwide Application Security Project) Foundation is a community producing open-source tools and best-practice for application software security. Recently it has published a guide on AI security and privacy, tying into broader software good practice and then tying into AI-specific attack surface areas and vectors. A good place to start exploring privacy and security considerations relating to AI models.
How self-learning models can outperform much larger LLMs
LLMs are often characterised by the size of the model (parameters) and their training data, with the presumption that bigger is better. Large models however come with the obvious disadvantages of computational cost and privacy protection. However a paper by an MIT professor describes how implementing self-training model, where the AI model uses its own prediction (via a process called textual entailment) to teach itself without human intervention. The resulting 350m parameter model outperformed models such as Google’s LaMDA and GPT models.
The secret inside GPT-4
OpenAI has kept the inner workings of GPT-4 well under wraps, maintaining their aura as leaders in generative language models, with much speculation as to how GPT-4 is able to outperform its predecessors. A blog post this week says that there isn’t an underlying algorithmic or model breakthrough or a much larger model. Instead, GPT-4 connects 8 different models together in an unspecified way. It feels to me that OpenAI is now moving towards keeping the fundamental model structures to itself, presumably to maintain the edge in real-world performance it appears to have over its competitors.
The thorny issue of copyright and generative AI
The implications of the use of intellectual property being used in training sets of generative AI models, first arose with image-generating AI and has spawned a number of lawsuits, including one by Getty Images against Stable AI for copyright. It is however virtually impossible to tell with certainty whether a work was including in the training of a Large Language Model. For this reason, the EU are proposing to require companies to disclose the data used when training their models, so as to protect the creators of intellectual property, thereby creating licensing models for AI. We are beginning to see the beginnings of these commercial relationships, with Microsoft, Google, OpenAI and Adobe negotiating with media and information organisations such as News Corp, Axel Springer, New York Times and the Guardian.
GPT-4 is pretty good at Maths too (or Math, if you are American)
In a recent paper called “Let’s Verify Step-by-Step”, researchers at OpenAI describe how GPT-4 has improved the underlying model to solve maths problems. They applied a supervision model during training called “process supervision” in which feedback is provided on each step of the reasoning, and not simply on the outcome. The paper (see here) shows that this optimised model, based on GPT-4 can successfully solve 78% of problems in a test problem set, though does not provide information for vanilla GPT-4. Nevertheless, having experimented a bit myself, it is clear that GPT-4 currently is a lot more reliable at maths problems than GPT-3.5.
70% of developers aim to use AI
A survey by the developer chat site Stack Overflow released a couple of days ago showed that 44% of developers already use AI tools when coding, and a further 26% plan to do so soon. GitHub Copilot, a code completion tool is by far the most popular AI-powered developer tool, while ChatGPT is unsurprisingly the most used AI-enabled search tool. This clearly has implications for AI usage policies for companies, which are largely reticent to use such tools do the risk of IPR leakage.
Google introduces a framework for Secure AI.
Unimaginatively titled Secure AI Framework (SAIF), this initiative by Google brings good infosec practice into the artificial intelligence space. Its six pillars include building on established cloud and infrastructure security principles, implementing perimeter monitoring of inputs and outputs of AI models to detect anomalies, building the ability to scale to deal with automated attacks and creating fast feedback loops for vulnerability detection and mitigation.
GPT-4’s understanding of the world’s geography
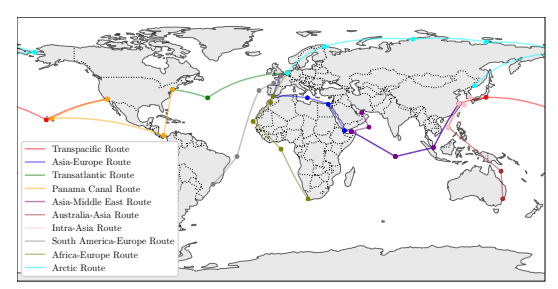
There have been several studies exploring large language models’ ability to understand different categories of information, including software, exam curricula and literature. In a paper published on arXiv, scientists at a number of universities discover the remarkable geographic understanding within GPT-4, which is able to return basic geographic data such as socio-economic indicators, and physical geography such as topography. More impressively, it can carry out route planning and figure out routes, such as key transport routes (maritime, rail and air). Whilst subject to hallucinations and missing data, it is really quite impressive.
Bloomberg’s purpose-built finance large language model
We have already seen many papers and articles on how generalist LLMs such as GPT-3 can be applied to solve problems across a broad range of domains. A couple of months ago, Bloomberg announced BloombergGPTTM , an LLM based on BLOOM with a 363 billion token dataset created from Bloomberg’s private archive of financial data, and augmented with a 345 billion token public data training set. In a paper published on arXiv, Bloomberg claims that this model outperforms larger, more-general purpose LLMs for tasks such as financial sentiment analysis, named entity recognition, and conversational reasoning of financial data. This is a remarkable case study for anyone considering creating a domain-specific LLM.
Will incumbents’ moats see off the waves of AI start-ups?
A few weeks ago, I explored the much-publicised clarion call of a Google researcher who claimed that Open Source will eat Google’s AI breakfast. Alberto Romero, a researcher at Cambrian AI takes a dissenting view, arguing that open-source models are tuned against closed-source models, through a process called self-instructing and consequently without incurring the prohibitive cost of training an LLM from scratch, open-source models will struggle to compete. Secondly, incumbents have access to millions of customers, which gives them an unparalleled route to market. We have already seen how Microsoft is integrating GPT into GitHub and its Office suite of productivity software, while Adobe’s FireFly has been wowing Photoshop users. Watch this space.
AI-assisted Writing and the Meaning of Work
Ethan Mollick, a Wharton professor, is one of the most insightful observers of the implications of AI. As Microsoft prepares to embed GPT-4 within its Office suite, it is surely only a matter of a few weeks before AI-assisted ‘Word’smithing becomes commonplace. What meaning and value do we assign to work that has only taken a few prompts to a generative AI system to create? The efficiency gains will be amazing, but expect it to be a bumpy ride.
Meta’s Multilingual Model supports over 1000 different languages.
We have already seen below the strides Meta is making, including on multi-modal foundation models. The rate of innovation shows no signs of abating, having recently open-sourced a multilingual model that was trained on 1,162 languages. To overcome the dearth of labelled datasets for many of the world’s languages, the researches used textual and audio data from religious texts, including the Bible, before unsupervised learning was applied to a further 4000 languages. The model was made available through extensions to Facebook AI’s popular PyTorch library.
The genesis of ChatGPT
The MIT Technology Review has a great story on how ChatGPT was released. What really stands out is how surprised the team at OpenAI were by how it became a viral sensation, and how the importance of accuracy has increased now that it is acting effectively as a search engine.
Will AI veer towards open or closed-sourced models?
Although Meta (i.e. Facebook) has not quite been hitting the AI headlines, its team, led by YannLeCun, is very active. One of its most significant contributions has been the release of LLaMA, a large language model trained on 1.4 trillion parameters. By sharing the code, the Meta team is hoping to drive faster innovation, particularly in adapting it to different use cases. Likewise, Stability AI has open-sourced its text-to-image model in the hope of benefitting from innovation amongst developers. Although a researcher at Google claimed that fighting Open Source is a “losing battle”, the size of these models means that they are trained by large tech companies, and it is unclear for how much longer this openness will persist.
Updated 23 May
Meta’s Multimodal AI Models
Multimodal AI models link different content types (e.g. text, audio, video) into a single index or ’embedding space’ and are increasingly a subject of much research. For example, AI image generators such as Midjourney and DALL-E link text decoders with image inference models. (See here for a good overview). Meta has announced an open-sourced AI model called ImageBind that brings together text, image, video, audio and sensor data (including depth, thermal and inertial measurements). For example, Meta claim that the model could create an image of a rainy scene from the sound of rain, or conversely add appropriate audio to a video sequence.
Updated 22 May
Large Language Model Landscape
With all the attention being heaped upon OpenAI’s ChatGPT, you’d be forgiven for thinking that GPT-3.5/4 was the only large language model in town. However, as a blog site maintained by Alan Hardman makes clear, this is an increasingly crowded space. The author helpfully also provides a list of LLMs, datasets , benchmarking and labs. An essential reference.
Updated 18 May
Annual Stanford AI Index Report
Not exactly a quick read, and I certainly have not yet been through it all yet, but if nothing else the key takeouts provide a quick snapshot of the state of AI. Points of interest are that industry has firmly taken over from academia in creating new AI models (not coincidentally the exponential increase in training compute continues), Chinese universities lead the world in AI publications and AI models performance continues to improve, with some categories out-performing the human baseline (such as language inference). A good long read.
Microsoft researchers make claims on Artificial General Intelligence
It is said that one way to destroy your credibility in the AI space is to claim that you have built a system capable of Artificial General Intelligence. This is generally taken as being an AI system that can be applied to a number of unrelated fields, achieving a level of capability similar or exceeding human capabilities. Cade Metz, who recently broke the news of Geoffrey Hinton’s AI concerns reports that researchers at Microsoft recently published a paper stating that GPT-4 is demonstrating ‘sparks’ of AGI that surprised the researchers. They describe a number of tasks that it was able to carry out including (rather incredibly) write a rhyming proof that there are an infinite number of prime numbers.
Updated 15 May
OpenAI Improves ChatGPT Privacy
Addressing concerns in many jurisdictions about the privacy impact of ChatGPT (such as Italy which temporarily banned its use), OpenAI has introduced features to allow individuals and organisations to request that they do not appear in answers via a Personal Data Removal Request Form. This is however only the opening gambit and is unlikely to satisfy regulators, as it has no bearing on whether data (correct or otherwise) can be restricted from training, and the risk of your chat history influencing the answers it gives other users.
Updated 13 May
How do Transformers Work?
Hugging Face, a company that provides AI models and datasets to developers offers a free online course on natural language processing (NLP) which contains a nice overview of the workings of the transformer, the AI architecture that underpins most modern large language models. For those of a more technical bent, you can read the original paper where Google scientists first described the transformer model and its attention mechanism. [Updated 22 -May] For further, more accessible, descriptions of the transformer model, see Transformers from Scratch by Peter Bloem, who also offers code in github and a few video lectures.
Updated 12 May
Size does not always matter
An article by the IEEE argues that there isn’t an inexorable correlation between size and model performance and that smaller models trained on larger datasets can outperform larger models. The cost of training between these two scenarios is unclear, but this may be the start away from a ‘number of parameters’ arms race, or “my model is bigger than yours” debate. Sam Altman, CEO of OpenAI made similar point at an MIT conference last month.
Updated 11 May
A look at ChatGPT’s Code Interpreter – A program that creates programs
The dystopian scenario that keeps AI pessimists alive is a future where AI systems are able to generate new AI systems, getting into a runaway loop of ever-improving capability which humans are powerless to stop. I am quite sceptical of this scenario, but GPT-4’s code interpreter, a sandboxed environment where GPT-4 can create, run and improve Python code is quite amazing, a preview of a world to come, and one that is particularly well-suited for complex data analysis.
Stanford University study on the impact of AI assistants on productivity
It has often been claimed that Artificial Intelligence can do for white-collar work what automation has already done for manufacturing. This is a viewpoint I subscribe to, and Stanford University’s Human-Centered Artificial Intelligence (HAI) centre has shown that call centre workers at a Fortune 500 software companies did indeed see an average of 13.8% productivity increase. Of particular note, the AI assistant was able to accelerate the up-skilling of workers, reaching productivity levels in two months that would previously have taken six months.
Updated 9 May
Google and OpenAI struggling to keep up with open-source AI
A Google researcher claims that the current generation of Large Language Models do not have any intrinsic insurmountable defenses, and that the threat/opportunity (depending on your vantage point) of open-sourced AI models was being overlooked. Following the leaking to the public of Meta’s open-sourced LLaMA model, a flurry of innovation has resulted in models being trained for as little as $100 worth of cloud compute.
WIRED, The Hacking of ChatGPT is Just Getting Started
An insight into what it means for a large language model to be compromised, the techniques being used to bypass ChatGPT’s safeguards, and how the field of Generative AI vulnerability and security research is still in its infancy.
Cade Metz, Genius Makers
For a fast-moving history of how a collection of doctoral students, researchers and academics persevered for years in relative obscurity before being suddenly cast into the spotlight as they became the most sought-after talent in tech. Charting the genesis of companies that are now household names such as DeepMind and OpenAI, Genius Makers tells the story of the multi-million tussle between Silicon Valley giants as they raced to assemble the best AI teams to build systems that can lay claim to human or super-human intelligence. Fascinating reading, especially as this book was written before generative systems exploded into the public consciousness.
The Economist – Special AI Edition
The Economist starts its special edition on artificial intelligence with an essay that takes the long view on the impact AI may have on humans’ sense of self and exceptionalism. Comparing it to the invention of printing, the dawn of the world wide web, and psychoanalysis, the essay posits that advances in AI will also lead to a reassessment of how humans understand the world. Are LLMs simply sequencing words, or is something more fundamental emerging? Less controversial but equally enlightening articles on how ChatGPT works (self-attention models), and whether they provide societal-level risks.
A paid-for
Thank you for sharing this curated list of AI articles, Simon! It’s clear that AI is rapidly evolving and influencing various aspects of our lives. The diversity of topics in your list reflects the breadth of AI’s impact, and it’s great to see that you’re continuously updating it.